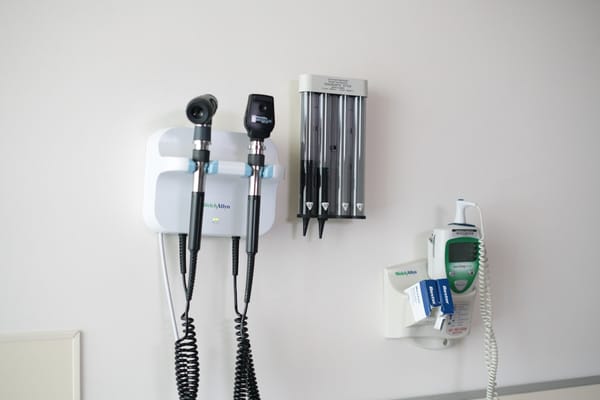
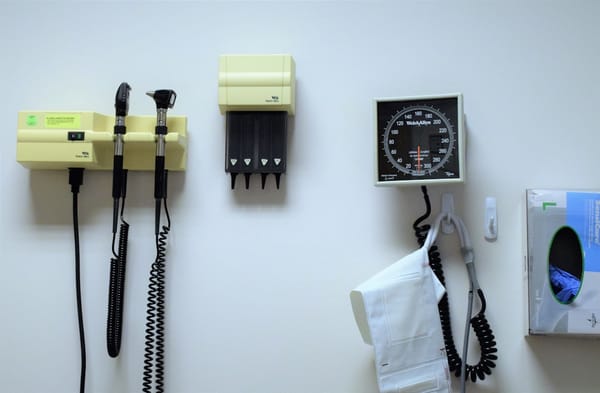
Web3项目
Solana Mobile SKR 上线后,空投不再只是拉新:一文看懂 Web3 手机生态的分配逻辑
Solana Mobile SKR 上线后,空投不再只是“拉新”:一文看懂 Web3 手机生态的分配逻辑 先说结论 Solana Mobile 在 2026 年推进 SKR 上线与空投,本质上不是一次短期营销,而是把“手机硬件用户、应用分发、链上激励”绑成一个可持续增长闭环。对普通用户来说,重点不在“能领多少”,而在“这个生态是否有持续使用价值”。 这件事的核心问题 过去很多空投项目的共同问题是: * 前期靠补贴冲用户,后期留存塌陷。 * 代币和产品价值脱节,空投结束后热度归零。 * 用户行为围绕“刷任务”而不是“真实使用”。 SKR 这类“硬件绑定型代币”尝试解决的是:把分发对象从“全网羊毛党”收缩到“真实设备用户与生态参与者”,提高激励效率。 关键机制拆解 1) 分发对象从“